自然語言處理的演進:從碎片化人工智慧到基礎模型
定義
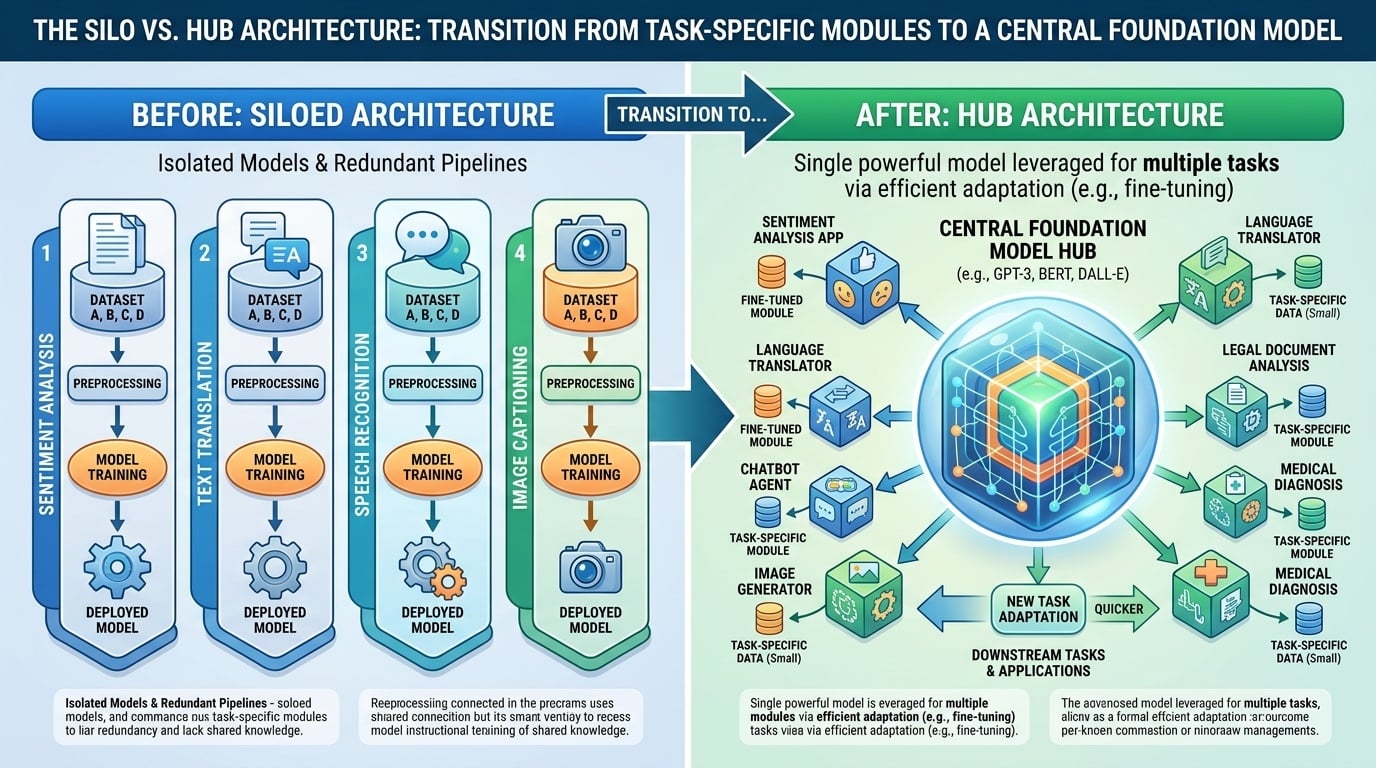
- 碎片化人工智慧:一個以獨立、專門的神經架構為特徵的時代,這些架構專為特定任務(如序列標記或分類)而設計。
- 基礎模型:一種整合性的單一結構變壓器架構,將所有語言問題視為生成式文本到文本的序列 $x \rightarrow y$。
核心概念
- 架構整合: 過去,自然語言處理需要量身訂作的流程(例如命名實體辨識使用 Bi-LSTM,情感分析使用 CNN)。大語言模型則將這些孤島式架構整合為單一主幹,使相同的權重可應用於所有任務。
- 統一介面: 大語言模型以自然語言介面取代專用的「輸出頭」(例如三類 Softmax)。輸入與輸出始終為字串,使模型能理解 意圖 而非 格式。
- 知識傳遞: 傳統模型對每項任務皆為「白紙狀態」。大語言模型則強調 先求泛化,即特定任務僅是基於已存在的穩固語言內在表示的應用。
歷史背景
- 2018 年以前: 任務隔離需針對不同損失函數 $\mathcal{L}_{task}$ 訓練不同的模型。
- 現代時代: 「文字對文字」的范式讓單一模型(例如 Llama-3)能透過零樣本或少樣本提示來切換任務。
Python 實作對比